Seungjae (Jay) Lee
이승재
I am a Ph.D. student in the Department of Computer Science at UMD, where I am fortunate to be co-advised by Prof. Furong Huang and Prof. Jia-Bin Huang.
Prior to joining UMD, I earned my Master's degree in the Department of Aerospace Engineering at SNU, where I was fortunate to be advised by Prof. H. Jin Kim. I also had the wonderful opportunity to work on robot learning with Prof. Lerrel Pinto of NYU.
Before that, I received Bachelor's degrees in Mechanical and Aerospace Engineering at SNU.

News
- Started internship at NVIDIA GEAR team
- TraceGen is accepted to CVPR 2026
- MomaGraph is accepted to ICLR 2026
Education & Experiences
Education
Ph.D. in Computer Science
University of Maryland
Advised by Professor Furong Huang and Professor Jia-Bin Huang.
Aug 2024 - Present | College Park, MD
M.S. in Aerospace Engineering
Seoul National University
Advised by Professor H. Jin Kim.
Mar 2021 - Feb 2024 | Seoul, Korea
B.S. in Mechanical & Aerospace Engineering
Seoul National University
Mar 2015 - Feb 2021 | Seoul, Korea
Experiences
NVIDIA
GEAR Team Research Intern
May 2026 - | Santa Clara, CA
Toyota Research Institute
Large Behavior Model Team Research Intern
May 2025 - Aug 2025 | Cambridge, MA
New York University
Research collaborator (Remote), advised by Professor Lerrel Pinto.
Jul 2023 - Jun 2024 | Seoul, Korea (Remote)
Samsung Electronics
Deep Learning Algorithm Team Intern
Jul 2020 - Sep 2020 | Gyunggi-do, Korea
Research
My research interest is understanding the interaction between agents and environments, and devising data-efficient decision-making (or robot learning) algorithms. Selected publications are marked with ★ below.
Seungjae Lee*, Yoonkyo Jung*, Jusuk Lee, Jonghun Shin, Amir Hossein Shahidzadeh, Yao-Chih Lee, H. Jin Kim, Jia-Bin Huang†, Furong Huang† (*equal contribution, †equal advising)
arXiv, 2026
Under review
project website / arXiv
Zhi Wang, Botao He, Kelin Yu, Seungjae Lee, Ruohan Gao, Furong Huang, Yiannis Aloimonos
arXiv, 2026
Under review
project website / arXiv / github
Jusuk Lee, Seungjae Lee, Jonghun Shin, Hoseong Jung, Sungha Kim, Daesol Cho, H. Jin Kim, Jia-Bin Huang†, Furong Huang† (†equal advising)
arXiv, 2026
Under review
project website / arXiv
Jeremy A. Collins, Seungjae Lee, Rachanon Wachakorn, Krishnan Srinivasan, Animesh Garg, Vitor Campagnolo Guizilini, Paarth Shah
arXiv, 2026
Under review
project website

Zikui Cai, Shivin Dass, Seungjae Lee, Kaushal Janga, Tan Dat Dao, Mingyo Seo, Kaiyu Yue, Mintong Kang, Nandhu Pillai, Monte Hoover, Aadi Palnitkar, Ruchit Rawal, Ruijie Zheng, Bo Li, Yuke Zhu, Roberto Martín-Martín, Tom Goldstein, Furong Huang
IROS, 2026
Seungjae Lee*, Yoonkyo Jung*, Inkook Chun*, Yao-Chih Lee, Zikui Cai, Hongjia Huang, Aayush Talreja, Tan Dat Dao, Yongyuan Liang, Jia-Bin Huang, Furong Huang (*equal contribution)
CVPR, 2026
project website / arXiv / github
Yuanchen Ju, Yongyuan Liang, Yen-Jen Wang, Nandiraju Gireesh, Yuanliang Ju, Seungjae Lee, Qiao Gu, Elvis Hsieh, Furong Huang, Koushil Sreenath
ICLR, 2026 (🏆 Oral)
project website / arXiv
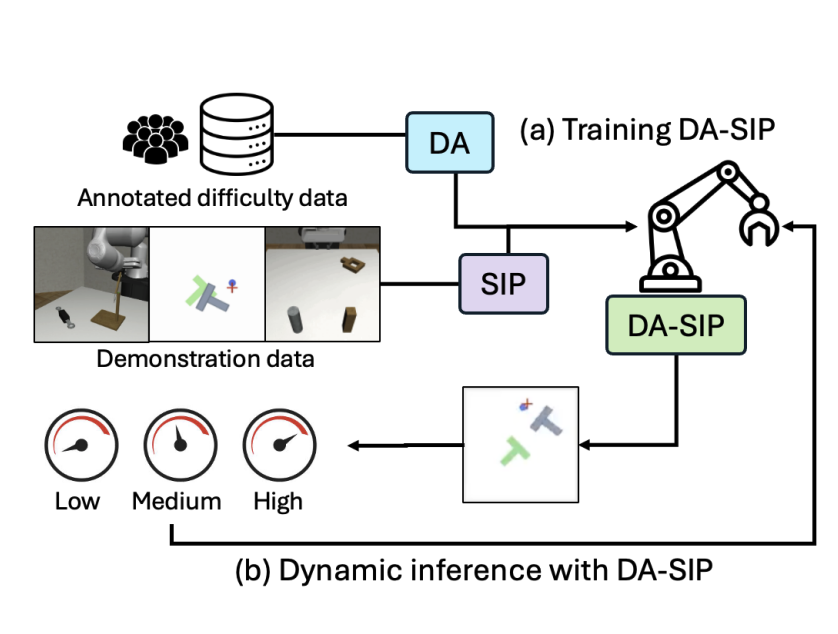
Inkook Chun, Seungjae Lee, Michael Samuel Albergo, Saining Xie, Eric Vanden-Eijnden
NeurIPS, 2025
arXiv / github
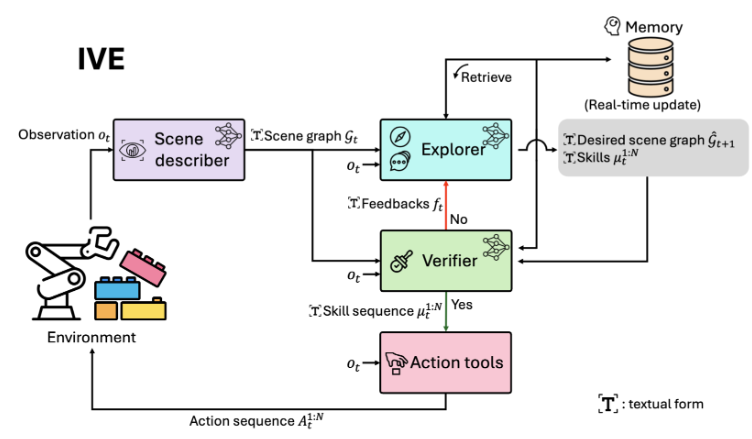
Seungjae Lee*, Daniel Ekpo*, Haowen Liu, Furong Huang†, Abhinav Shrivastava†, Jia-Bin Huang† (*equal contribution, †equal advising)
CoRL, 2025
project website / arXiv
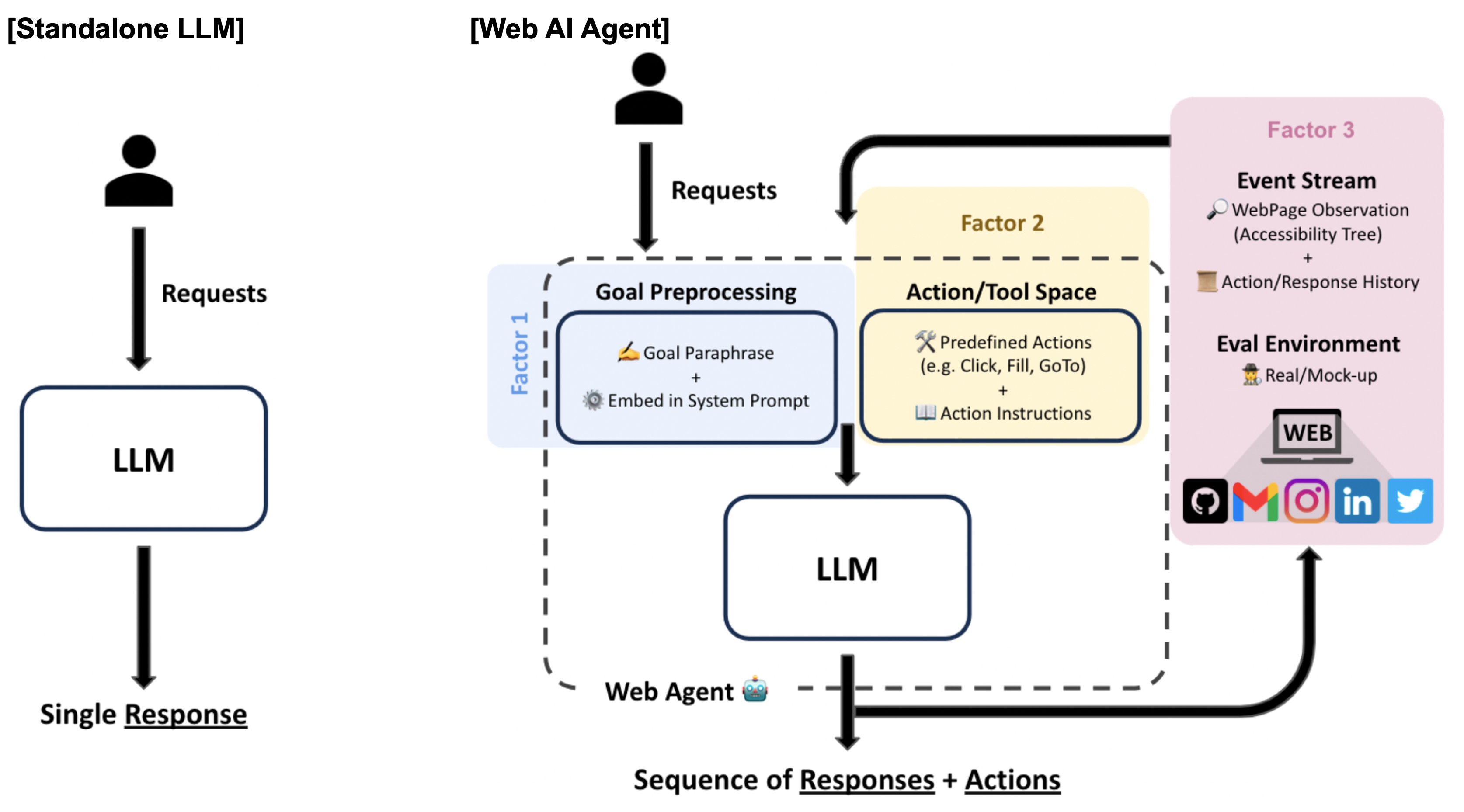
Jeffrey Yang Fan Chiang*, Seungjae Lee*, Jia-Bin Huang, Furong Huang, Yizheng Chen (*equal contribution)
ICLRw, 2025
project website / arXiv
Haritheja Etukuru, Norihito Naka, Zijin Hu, Seungjae Lee, Julian Mehu, Aaron Edsinger, Chris Paxton, Soumith Chintala, Lerrel Pinto, Nur Muhammad Mahi Shafiullah
ICRA, 2025
project website/ paper/ github
CoRL 2024 Workshop on Language and Robot Learning (🏆 Oral)
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H. Jin Kim, Nur Muhammad Mahi Shafiullah, Lerrel Pinto
ICML, 2024 (🏆 Spotlight, Top 3.5%)
project website / arXiv / github / 🤗 Lerobot Library
RSS 2024 Workshop SemRob (🏆 Oral spotlights) ICML 2024 Workshop MFM-EAI (🏆️ Outstanding Paper Award - Winner)
Seungjae Lee, Daesol Cho, Jonghae Park, H Jin Kim
NeurIPS, 2023
arXiv

Daesol Cho, Seungjae Lee, H Jin Kim
NeurIPS, 2023
arXiv
Dongseok Shim*, Seungjae Lee*, H Jin Kim (*equal contribution)
ICML, 2023
arXiv / github
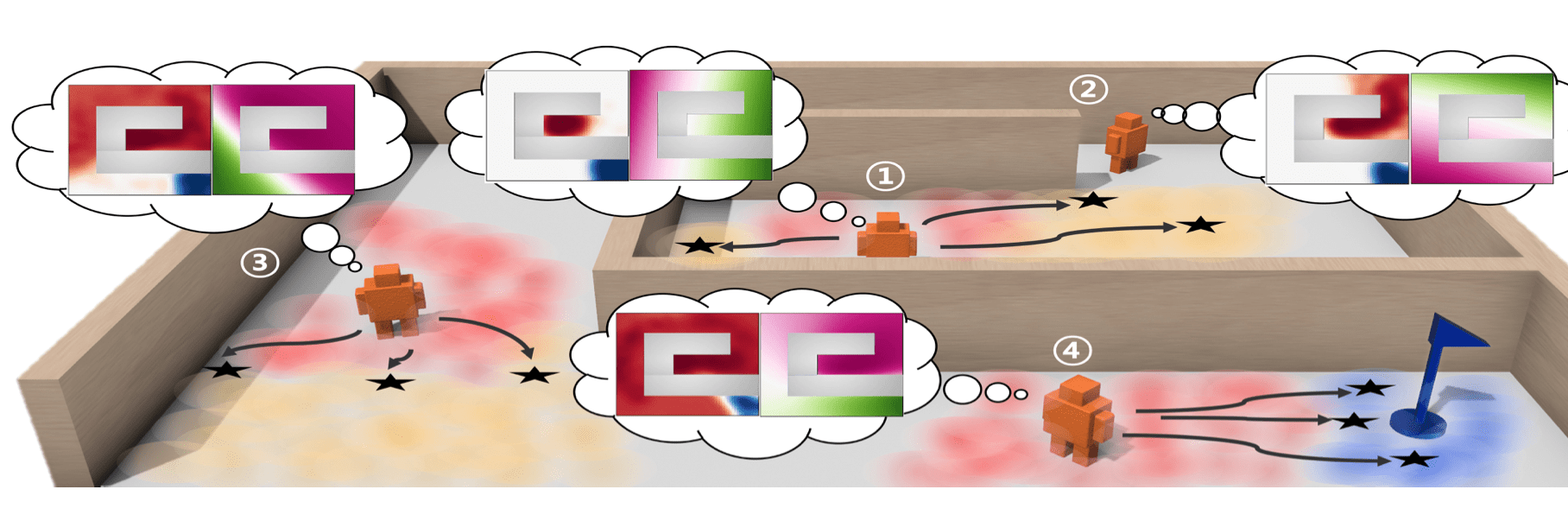
Daesol Cho*, Seungjae Lee*, H Jin Kim (*equal contribution)
ICLR, 2023 (🏆 Spotlight, Top 5.65%)
arXiv / github
Seungjae Lee, Jongho Shin, Hyeong-Geun Kim, Daesol Cho, H. Jin Kim
IJCAS, 2023
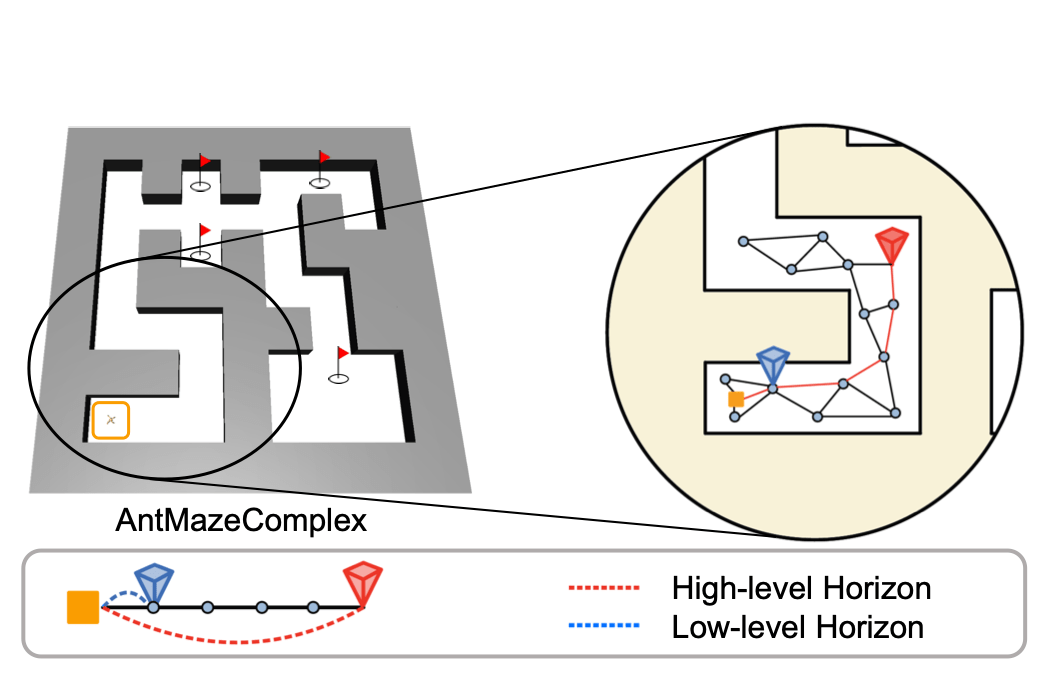
Seungjae Lee, Jigang Kim, Inkyu Jang, H. Jin Kim
NeurIPS, 2022 (🏆 Oral, Top 1.76%)
arXiv / github
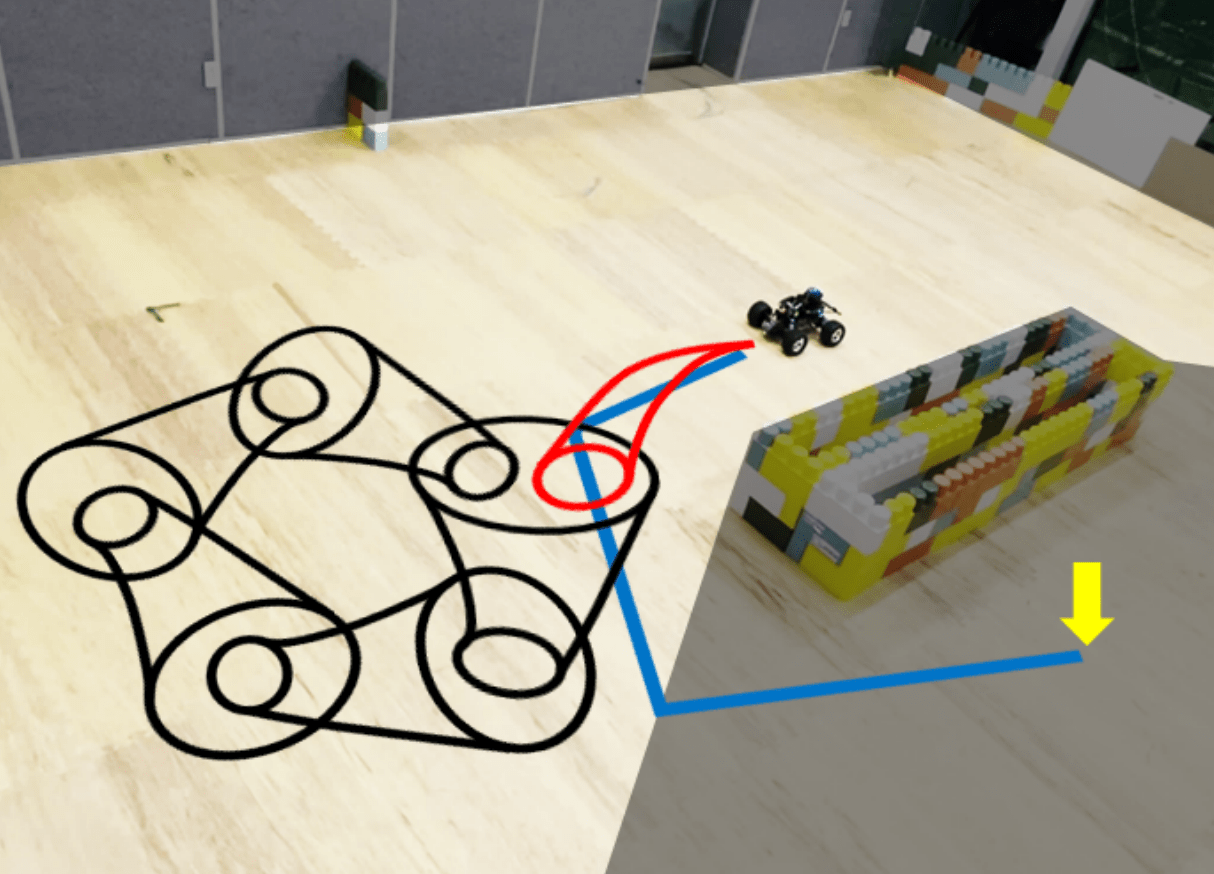
Inkyu Jang, Dongjae Lee, Seungjae Lee, H Jin Kim
IROS, 2021 arXiv
Awards and Achievements
- [Awards] Graduated Summa Cum Laude, Seoul National University (1st in Department of Aerospace Engineering)
- [Scholarship] Daishin Songchon Foundation (Aug 2024 - Present)
- [Scholarship] Hyundai Motor Chung Mong-Koo Foundation (Aug 2021 - Jul2023)
- [Scholarship] OK Bae & Jung Scholarship Foundation (Mar 2020 - Dec 2020)
Academic Services
- Program Committee, RSS 2024 SemRob Workshop
- Conference reviewer for ICML'22 '24 '25
- Conference reviewer for IROS'23
- Conference reviewer for NeurIPS'23 '25 '26
- Conference reviewer for ICLR'24 '25 '26
- Conference reviewer for ICRA'24 '25
- Conference reviewer for AAAI'25
- Conference reviewer for CoRL'25 '26
- Conference reviewer for RSS'25
- Conference reviewer for CVPR'26
Teaching
- [TA] Introduction to Datascience (CMSC320), University of Maryland (2026 Spring)
- [TA] AI Planning (CMSC722), University of Maryland (2024 Fall)
- [TA] Hyundai Motor Company AI Boosting Camp, Seoul National University (2023 Summer)
- [TA] Principles of Flight Vehicle Control (M2795.002600), Seoul National University (2021 Spring)
- [TA] Basic Physics 1 (034.005), Basic Physics 2 (034.006), Seoul National University (2016 Spring, 2019 Spring, 2019 Fall)